01
Designer
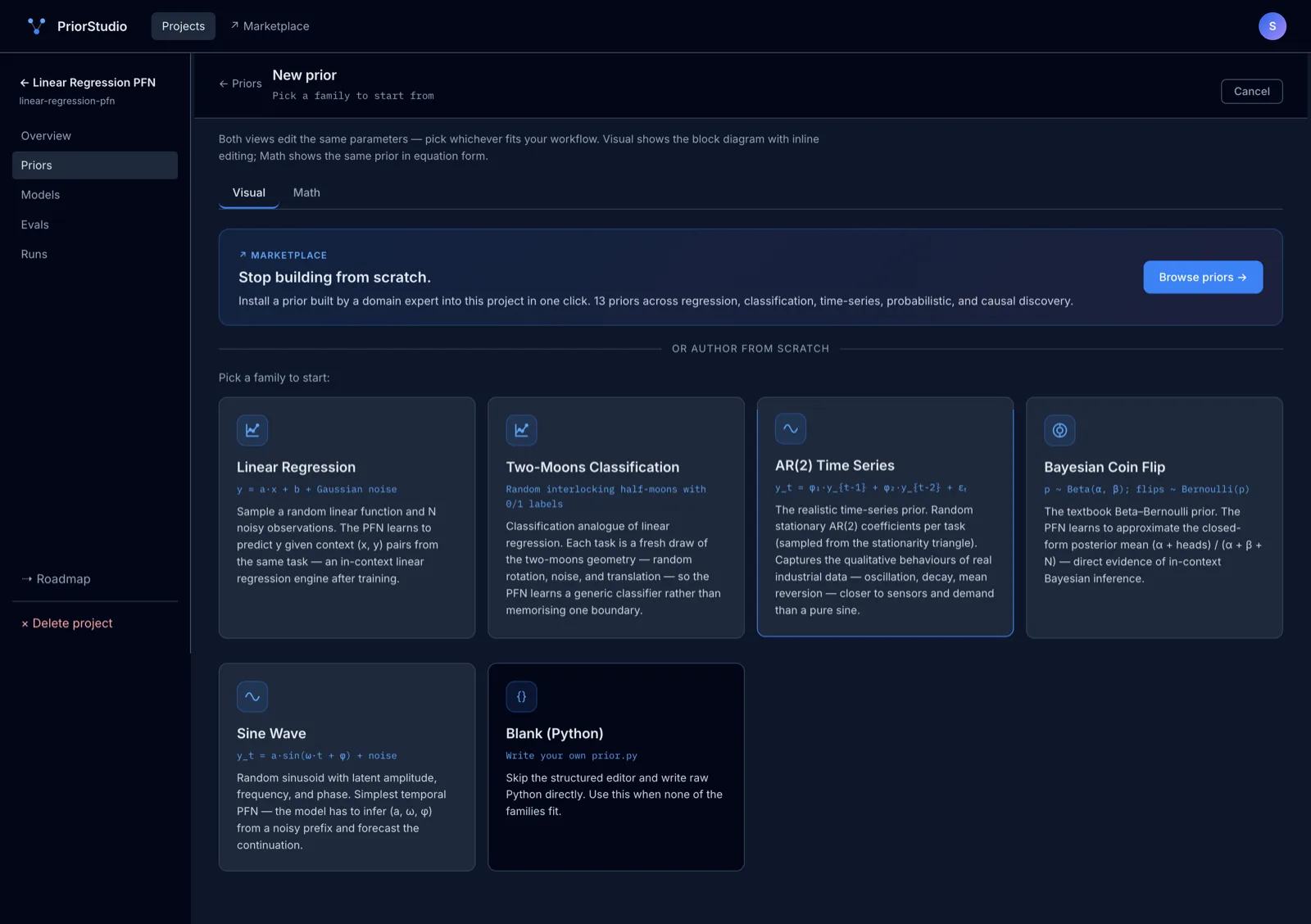
Author priors visually, in math, or in Python.
Block-diagram editor for the visual mode. Equation-form editor for the math mode. Raw prior.py for full control. Five built-in families to start from.
Click to expand →
Design priors, compose architectures, train, test, share — one place to build a foundation model for your domain. No data-generation code to write. No infra to glue.
Built on the prior-fitted networks architecture introduced in Müller et al., ICLR 2022. A prior is just Python code that generates synthetic training data — train on it once, get a model that does in-context inference on any real dataset of the same shape.
Build models that
Stop hand-rolling training loops and eval harnesses for every domain. Author once, the studio runs everything.
Get a working in-context model on your problem in minutes — fast enough to make it a prototyping tool, not a quarter-long project.
You know the physics or the data better than any ML team. Start from a prior that matches your domain — no PyTorch required.
Everything you need to take a foundation model from idea to a trained, shareable artifact — and nothing you don't.
Author priors visually, in math, or in Python.
Block-diagram editor for the visual mode. Equation-form editor for the math mode. Raw prior.py for full control. Five built-in families to start from.
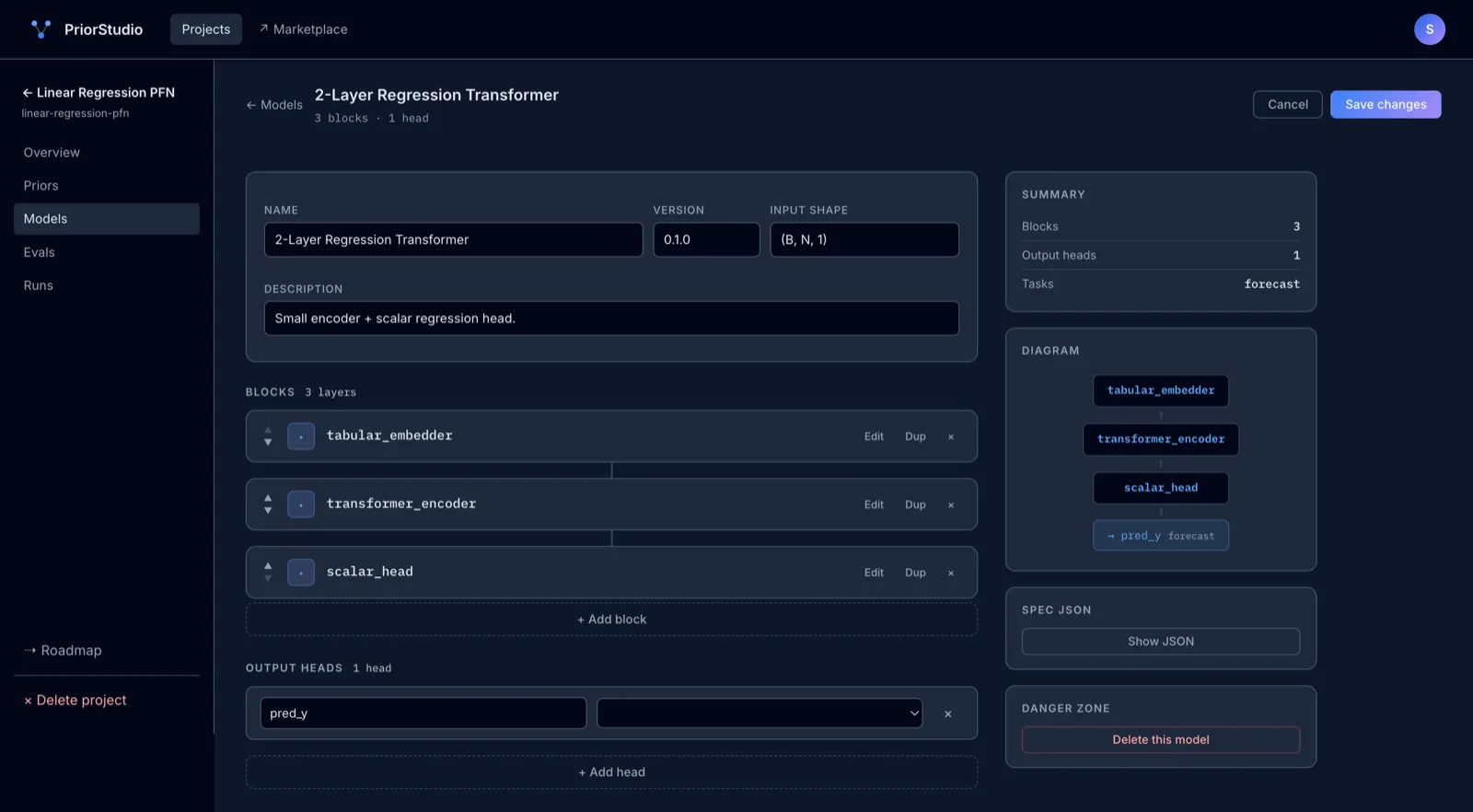
Compose architectures from blocks.
Drag tabular embedders, transformer encoders, attention pools, and task heads into a model spec. Add your own blocks with a single decorator.
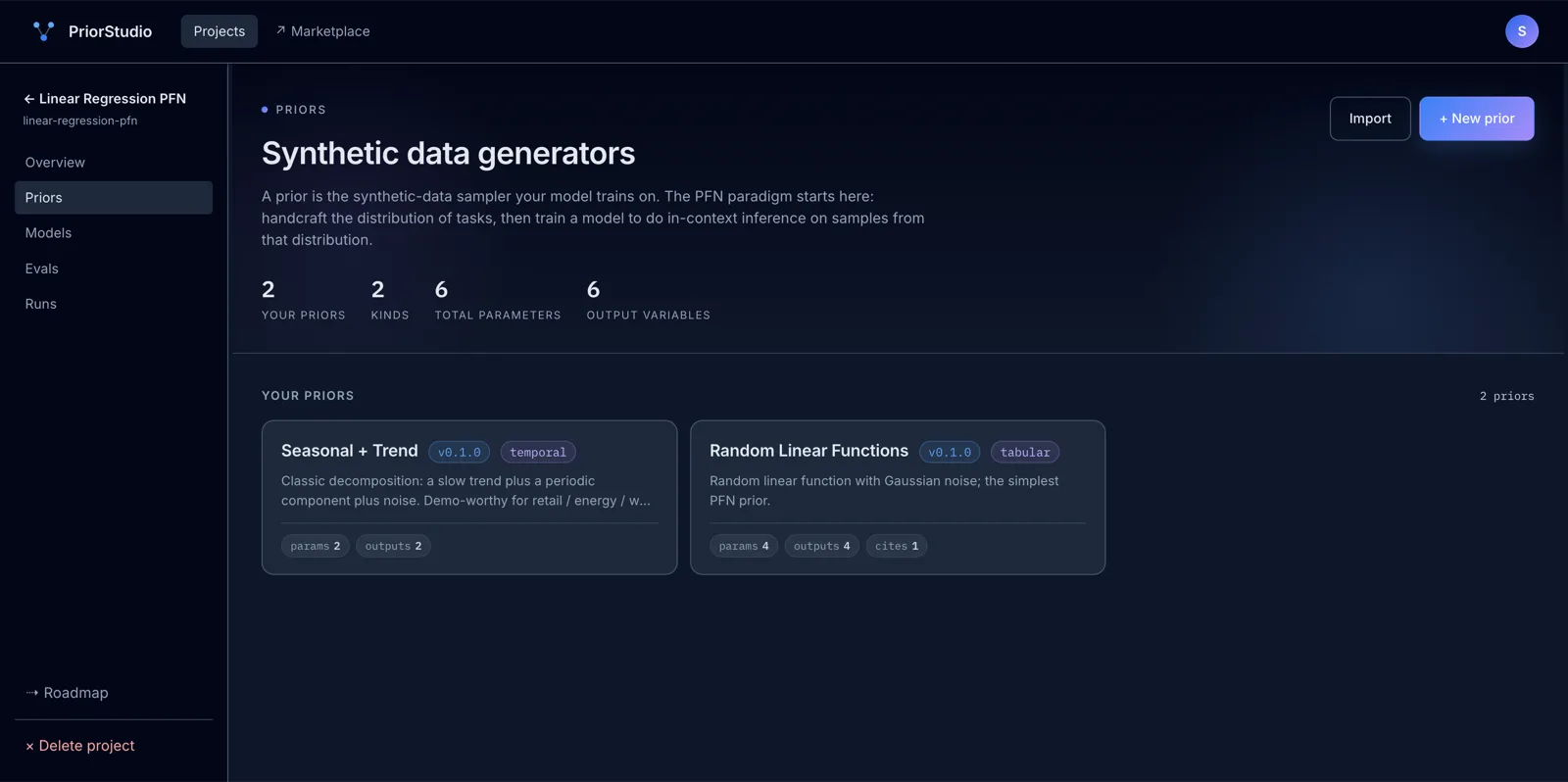
Start from a curated library of priors.
13 ready-to-train priors plus 6 model templates and 9 OSS PFN projects. Fork any of them into your workspace.
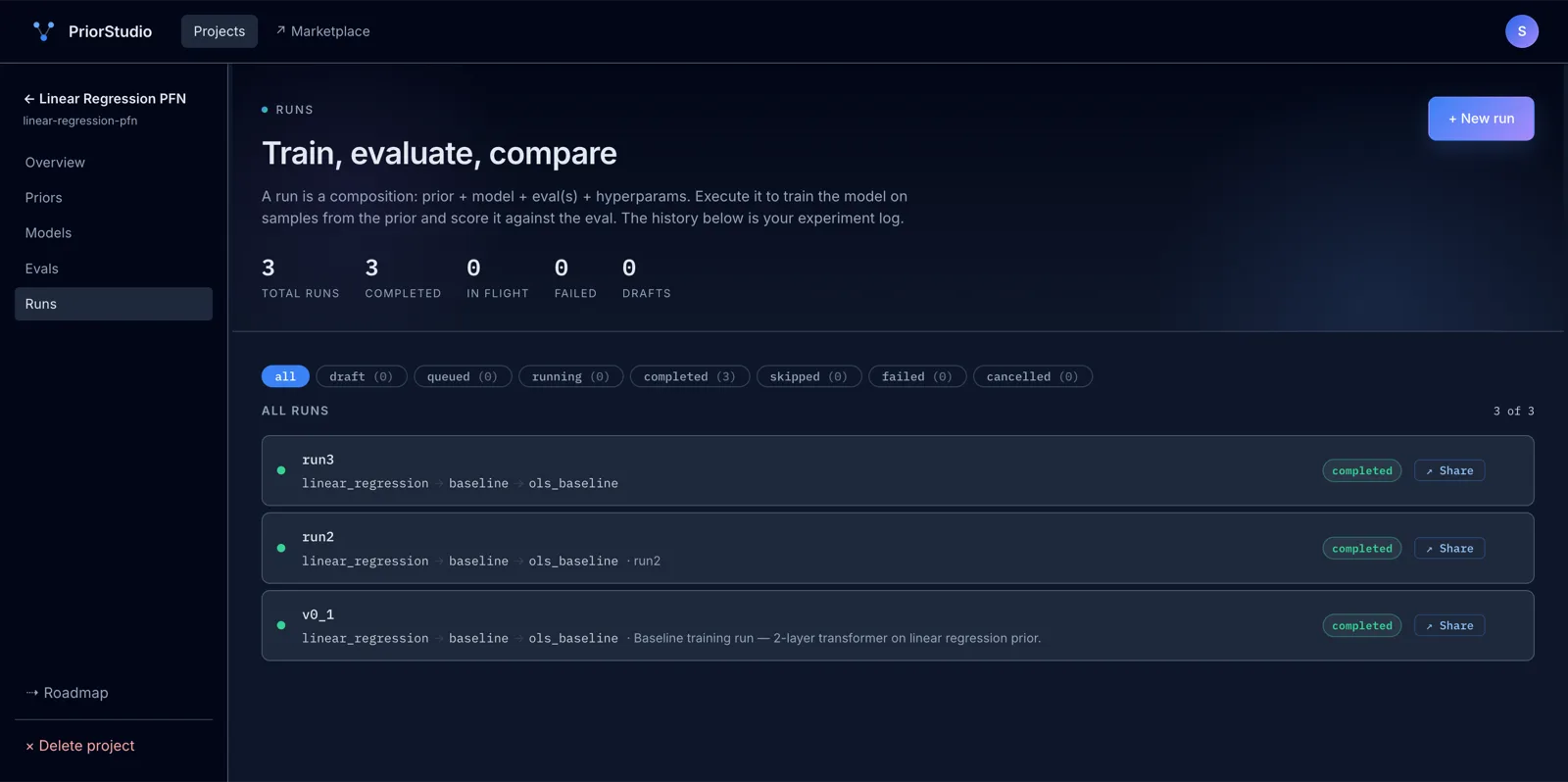
Train in the cloud, no setup.
Click Run and watch the loss curve update live in your browser — training happens on our infrastructure. CPU included during early access; GPU on demand as you scale.
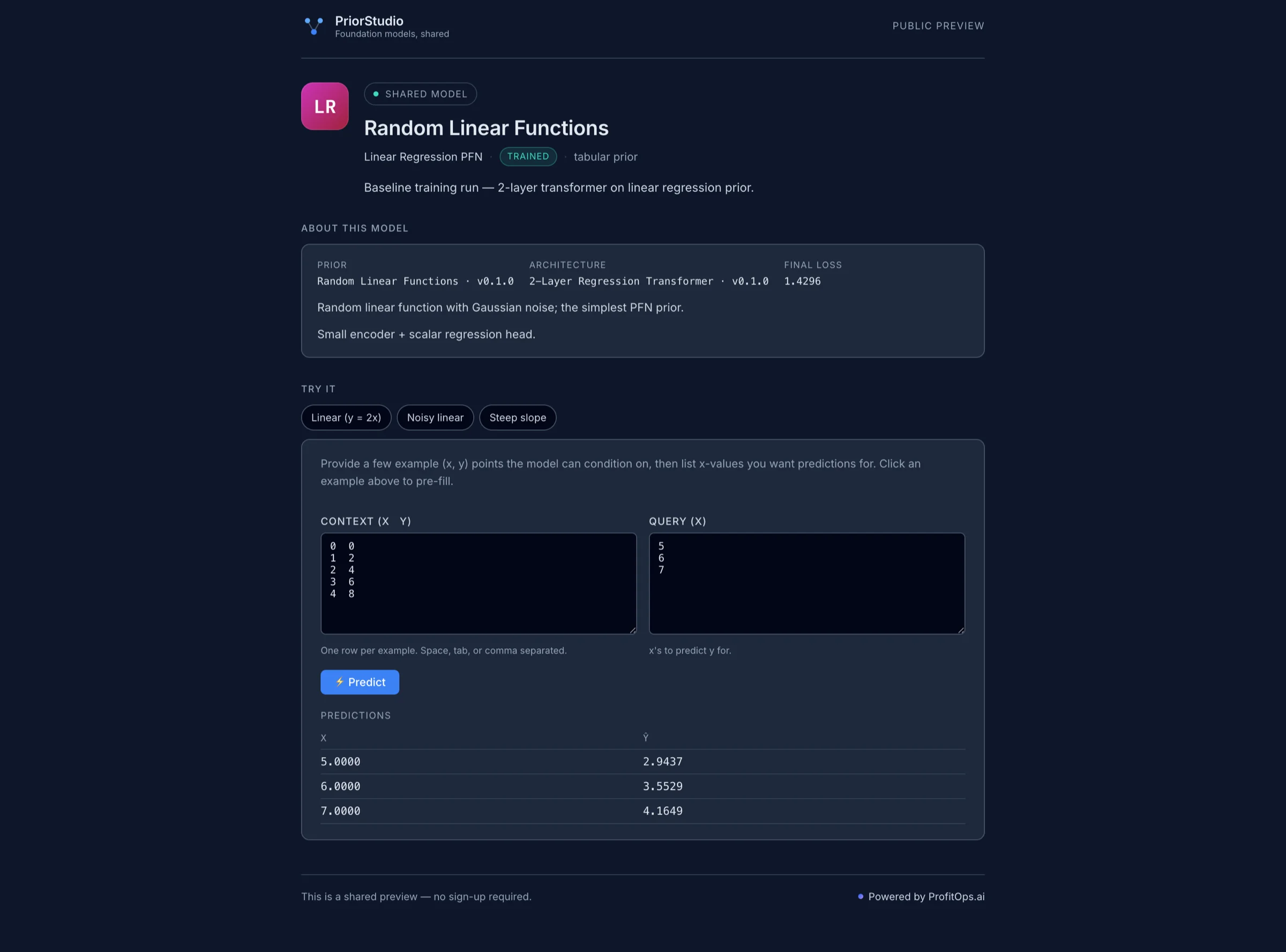
Public Try-it links per trained model.
Generate a public URL for any completed run. Recipients open a Try-it page, paste their data, get predictions — no sign-up required.
Every prior is a Python file plus a parameter spec — built by the community, validated against a baseline, ready to fork into your project.
The reference PFN prior. Random linear functions with Gaussian noise — the simplest demonstrable PFN training task.
Classification analogue of linear regression. Each task is a fresh draw of the two-moons geometry — the PFN learns a generic 2D classifier.
Real-world-shaped time series. Random stationary AR(2) coefficients per task; the PFN learns to forecast any well-behaved autoregressive series.
Random sparse linear structural causal models. The PFN outputs an adjacency matrix — pure structure discovery, no fitted edges.
Install from the marketplace, fork an existing one, or design your own in the visual editor. A prior is just Python that generates synthetic data the model can train on.
Hit ▶ Run. We spin up the training job on our infrastructure. You watch the loss curve update live, inspect every step, and fail loudly with structured error logs if something's off.
Try predictions in the in-product widget. Generate a public link, send it to a customer or colleague — they paste their data and see predictions without an account.
Most teams ship a foundation model by gluing six tools and writing a lot of YAML. PriorStudio collapses the stack so you spend time on the prior, not the infra.
What your customer sees
Short answers to the questions that come up most. Reach out at hello@profitops.ai if yours isn't here.
Free during early access. No credit card. No installs. We host the training.